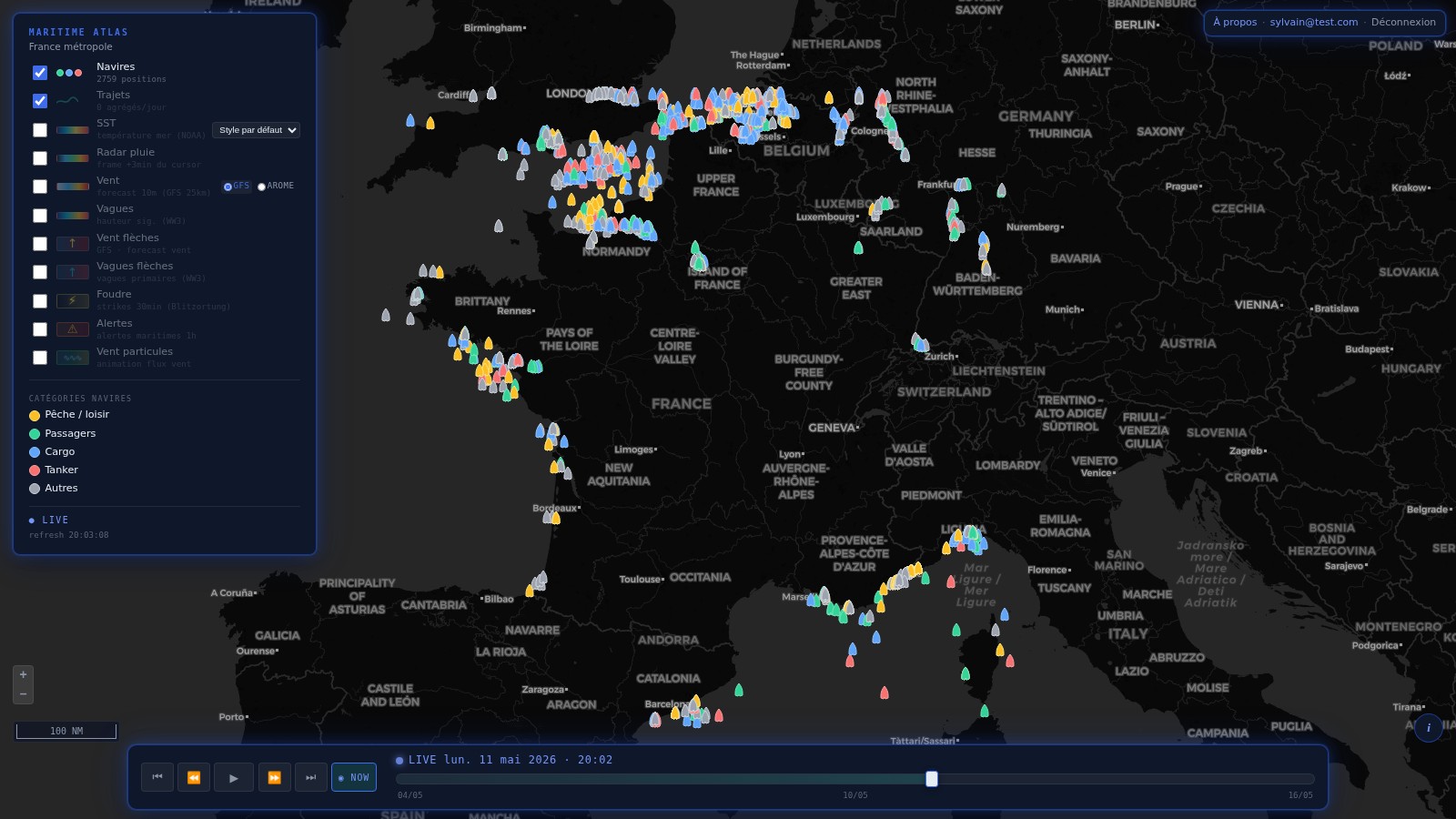
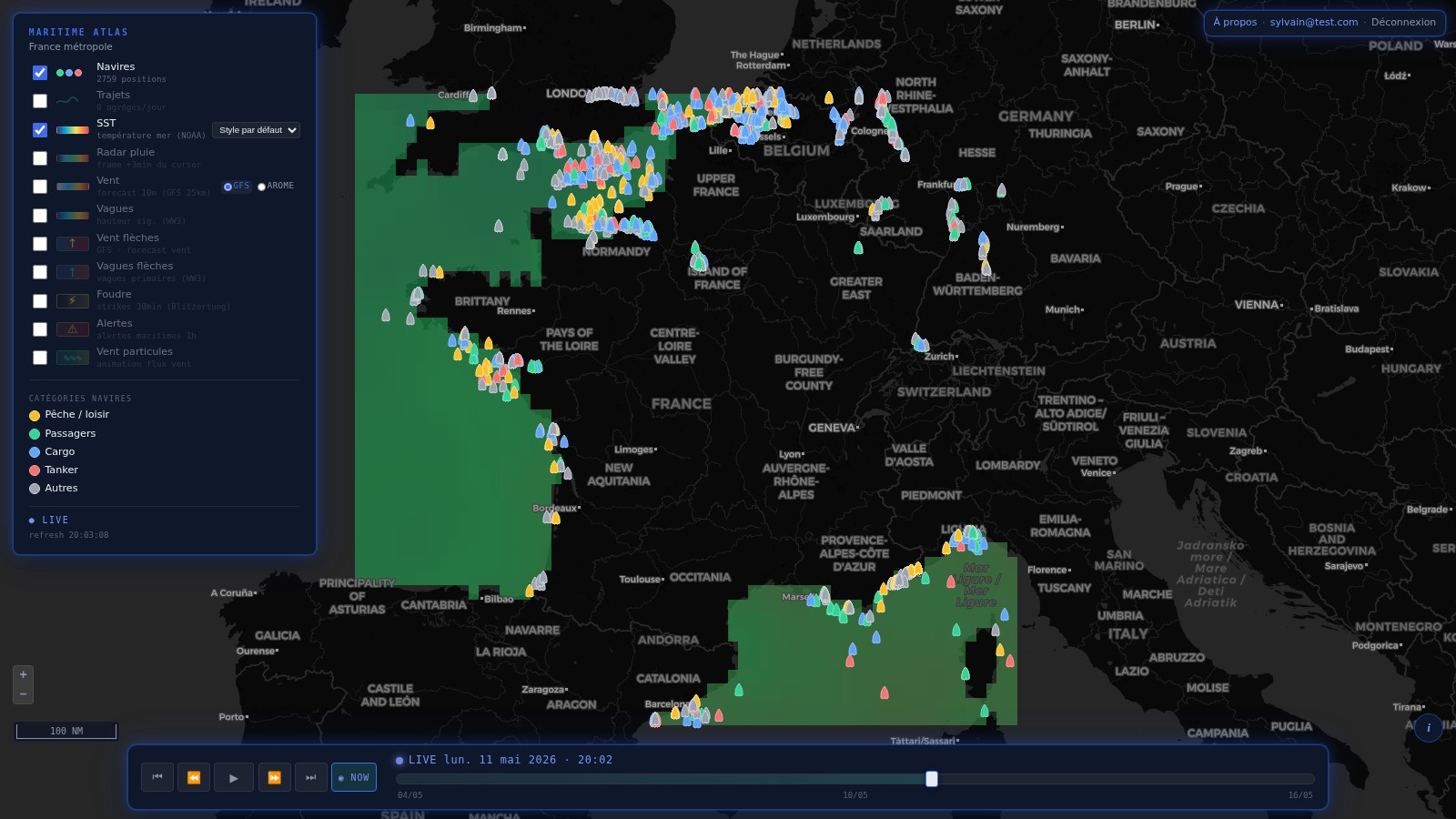
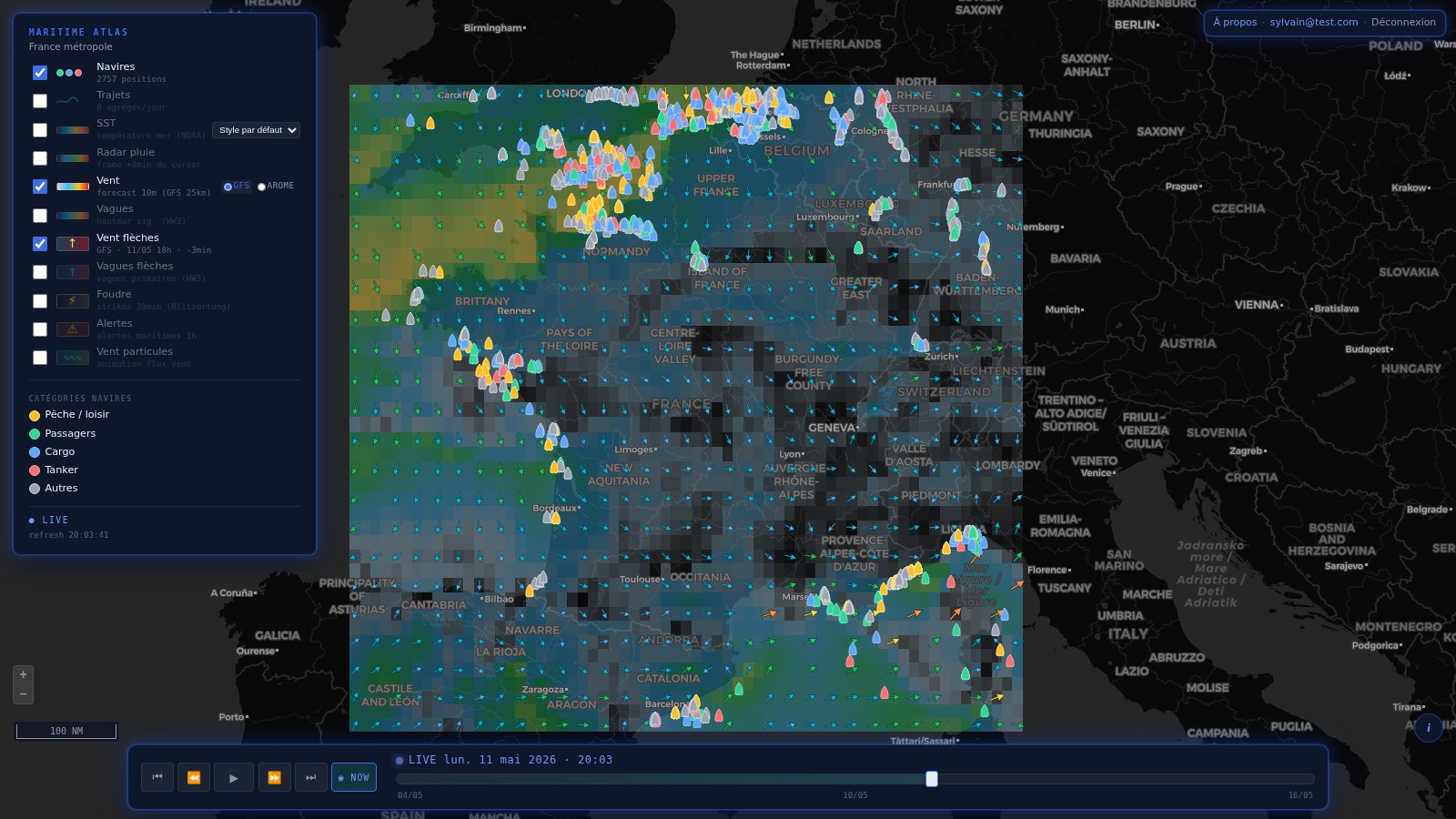
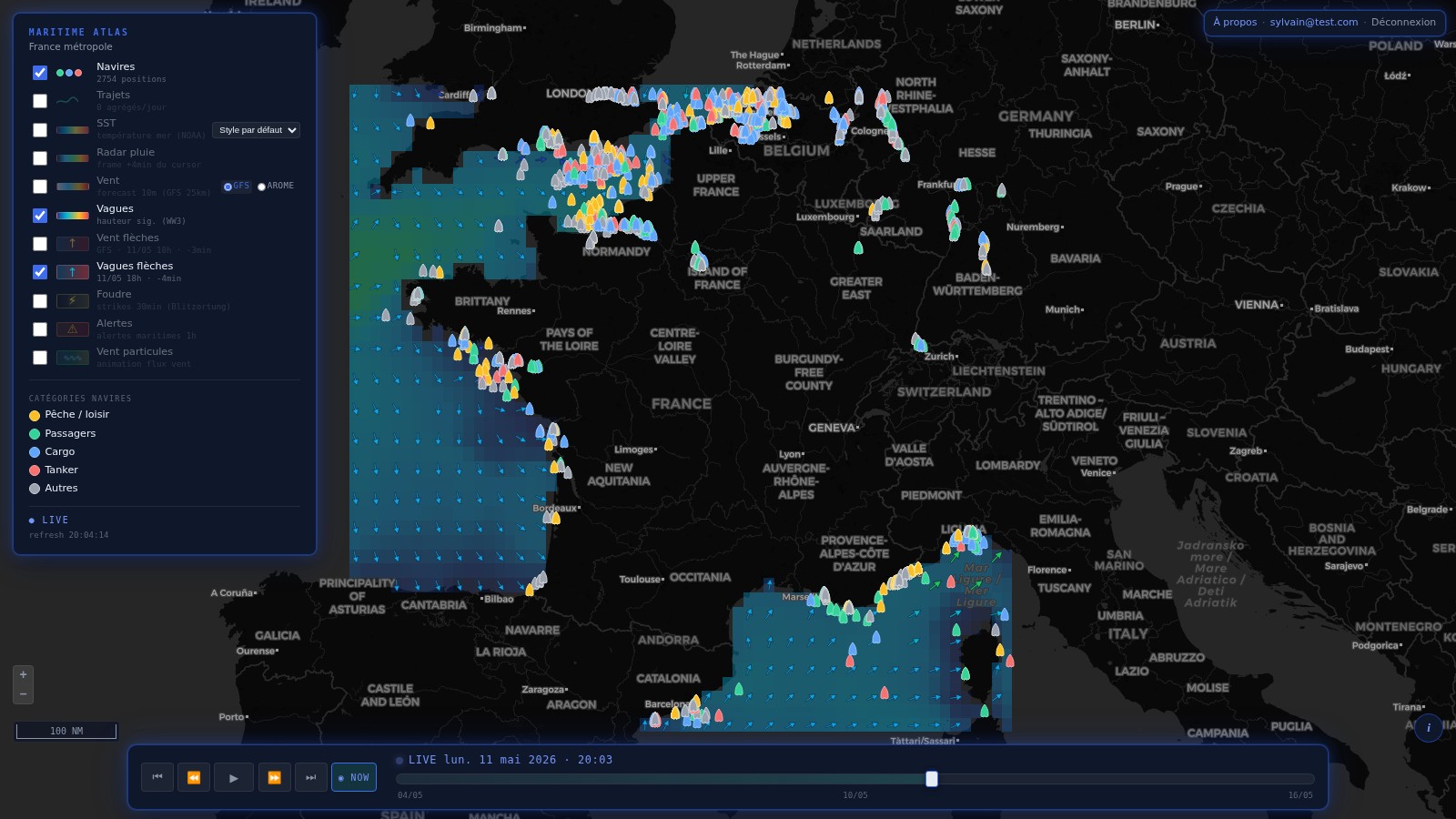
Les rasters source météo / océano sont sur grille grossière : GFS 0.25°
(~28km), OISST 0.25°, WW3 0.5°. Au rendu, on voit les pixels — pas joli,
et les isolignes ras:Contour sortent en escaliers. La solution
classique = densifier le raster côté serveur avant la color map. Mais
il ne faut surtout pas pré-sampler les données (les
rasters source doivent rester intacts pour GetFeatureInfo / WCS time
series). Donc : densification rendering-side uniquement.
On a écrit un plugin Java GeoServer WPS qui expose deux
processes custom :
-
idw:IDW — Inverse Distance Weighting raster densifier.
Paralléle sur les rangées dst (IntStream.range().parallel()),
fast paths pour p=1 (linear) et p=2 (squared, skip Math.pow),
Math.fma pour les sommes pondérées, factory cache static
final. ~150 lignes Java 17.
-
idw:IDWContour — appelle IDWProcess.execute()
puis ContourProcess.process() de GeoTools en interne, retourne
la FeatureCollection des isolignes lisses. Pourquoi pas un chaining
SLD natif ? Voir bug ci-dessous.
Le bug GeoTools post-2.26.2 — débuggé avec Claude en miroir
Je connaissais le bug depuis un projet pro avec un autre Claude — il avait
fini par trouver la régression dans les sources GeoTools, commit d'Andrea
Aime (le mainteneur historique). En SLD avec rendering transformation, la
syntaxe <Function name="parameter"><Literal>data</Literal></Function>
sans valeur déclenche une auto-injection du coverage source côté pipeline
de rendu. Sauf qu'à partir de GeoTools 32 (= GS 2.26.2), si le process
bean Java ne contient AUCUNE des méthodes
invertGridGeometry / invertQuery / customizeReadParams / clipOnRenderingArea,
AnnotationDrivenProcessFactory.create() wrap le process en
plain ProcessFunction au lieu de
InvokeMethodRenderingProcess — l'auto-injection ne se déclenche
plus, data arrive null, et l'execute() jette
"Parameter data is missing but has min multiplicity > 0".
Fix dans le plugin : ajouter une méthode publique
public GridGeometry invertGridGeometry(Query, GridGeometry)
qui retourne le target tel quel. Sa simple existence
détectée par réflexion suffit à déclencher le bon wrapping. Pas
d'implements RenderingProcess requis — la réflexion sur le
nom de méthode est plus permissive que l'interface elle-même.
Le chaining SLD reste cassé entre processes externes même
avec le fix : ras:Contour avec un idw:IDW nested
dedans → le inner ne reçoit toujours rien (GS n'auto-injecte que sur la
transformation externe). D'où idw:IDWContour qui internalise
les 2 étapes — un seul process, plus de chaining, plus de bug.
Le piège JDBCConfig — 1h perdue avant de comprendre
Le cluster GeoServer utilise JDBCConfig (catalog Postgres-backed) pour que
les 2 replicas partagent le même état. Quand on PUT un SLD via REST API
(PUT /rest/workspaces/<ws>/styles/<name>?raw=true), la DB
est bien mise à jour, et un GET sur la même URL retourne la nouvelle version
✓. Mais le rendu continue d'utiliser l'ancienne version
— pourquoi ?
Réponse : GeoServer charge les SLDs depuis le filesystem
(workspaces/<ws>/styles/<name>.sld), pas depuis la DB. Les
REST writes à JDBCConfig ne ré-écrivent pas les fichiers
SLD sur disque — ils restent stales. POST /reload recharge le
catalog depuis DB mais pas les fichiers SLD. Donc tant qu'on ne docker cp
pas le SLD dans chaque replica, le rendu reste figé sur l'ancienne version
— alors même que tous les indicateurs catalog disent "à jour".
Workaround durable : un script deploy-style.sh qui fait les 3
étapes (REST PUT + docker cp dans les N replicas +
POST /reload). Idempotent, déployable en CI/CD. Le drift
catalog ↔ disk n'est pas documenté côté GeoServer — leçon à graver dans
la mémoire des projets cluster JDBCConfig.
Burst protection — control-flow extension
Le frontend OpenLayers tile par tuiles 256×256 — un pan de carte peut
burst 30+ requêtes WMS GetMap en parallèle. Avec une rendering transformation
coûteuse (IDW densify × Contour), le pool de threads Tomcat saturait → LB
nginx en upstream timed out → cascade de 502 → GeoServer
s'effondrait pendant 1-2 minutes. Solution : l'extension stable
control-flow (Andrea Aime aussi, par contre celle-là est
documentée). On a calibré pour quad-core × 2 replicas Hazelcast :
ows.global=16, ows.wms.getmap=6,
user=8, timeout=30s. Les requêtes excédentaires
partent en file plutôt que de tuer le serveur.
Burst test validé : 30 requêtes WMS concurrentes → 30/30 réponses 200,
P95 = 6s (sous le timeout 30s), zéro 502, zéro effondrement.